```
效果如下:
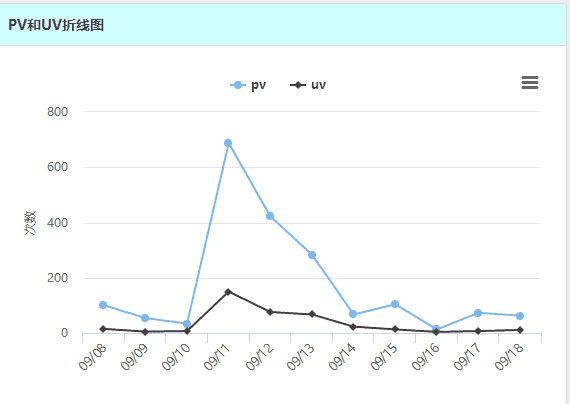
(2)地域访问量 在python代码中先获取地域的数据,其结果如下,百度统计跟echarts都是百度的,果然,自家人对自己人的支持真是特别友好的。
```html
[{'pv_count': 649, 'pv_ratio': 7, 'visitor_count': 2684, 'name': '广东'}, {'pv_count': 2, 'pv_ratio': 2, 'visitor_count': 76, 'name': '四川'}, {'pv_count': 1, 'pv_ratio': 1, 'visitor_count': 3, 'name': '江苏'}]
```
地域图目前支持最好的还是百度的echarts,使用方法见echarts的官网吧,这里不再阐述,展示**地域图**的时候需要获取下载两个文件,[china.js](http://echarts.baidu.com/download-map.html)(其提供了js和json,这里使用的js),[echarts.js](http://echarts.baidu.com/download.html)。 部分代码:
```jsp
```
结果如下: 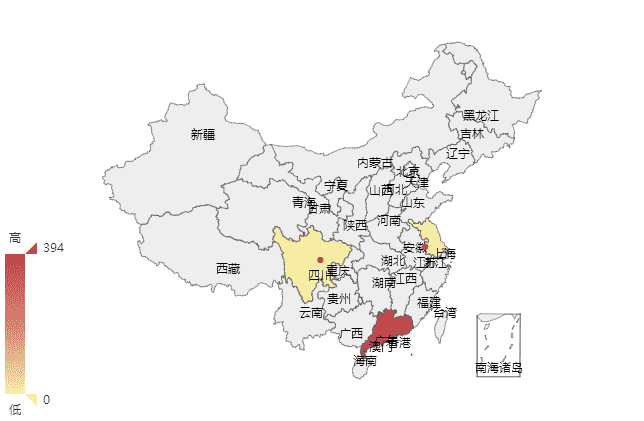
## 结语
网上关于日志系统的几乎都是ELK,对于小网站的,隐私不是很重要的还是可以用用百度统计的,这套系统也折磨了我挺久的,特别是它那反人类的返回数据。期初本来是想使用百度统计的,后来考虑了一下ELK,尝试之后发现,服务器配置跑不起来,还是安安稳稳的使用了百度统计,于此做成了这个系统,美观度还是不高,颜色需要优化一下。最后,希望能在GitHub上给我个star吧。\
日志系统地址:\
个人网站网址:\
个人网站代码地址:\
百度统计python代码地址:\
万分感谢
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://gitbook.wenzhihuai.com/ge-ren-wang-zhan/4.-ri-zhi-xi-tong.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.