> For the complete documentation index, see [llms.txt](https://gitbook.wenzhihuai.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://gitbook.wenzhihuai.com/ge-ren-wang-zhan/2.lucene-de-shi-yong.md).
# 3.2 Lucene的使用.md
首先,帮忙点击一下我的网站 。谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址 。
### Lucene的整体架构
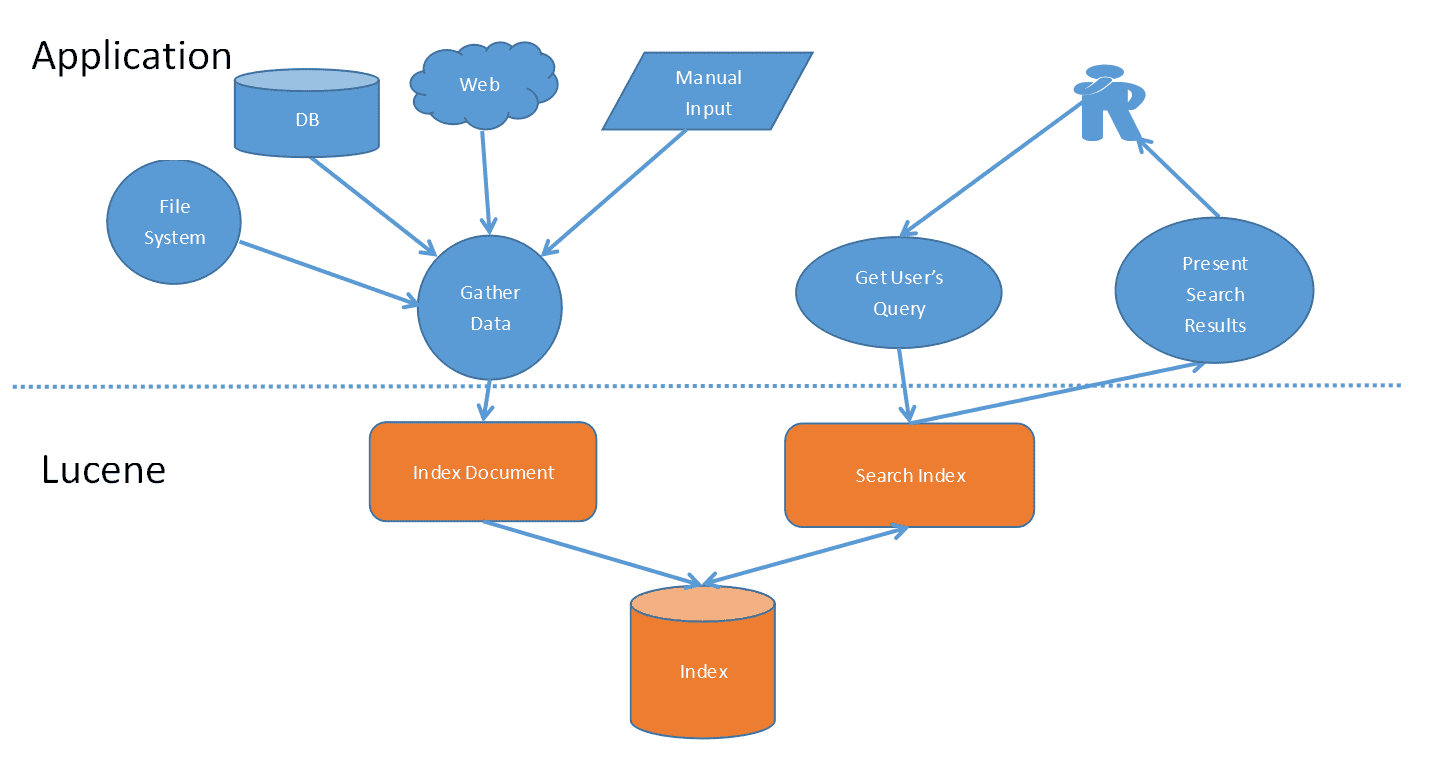
### 搜索引擎的几个重要概念:
1. 倒排索引:将文档中的词作为关键字,建立词与文档的映射关系,通过对倒排索引的检索,可以根据词快速获取包含这个词的文档列表。倒排索引一般需要对句子做去除停用词。 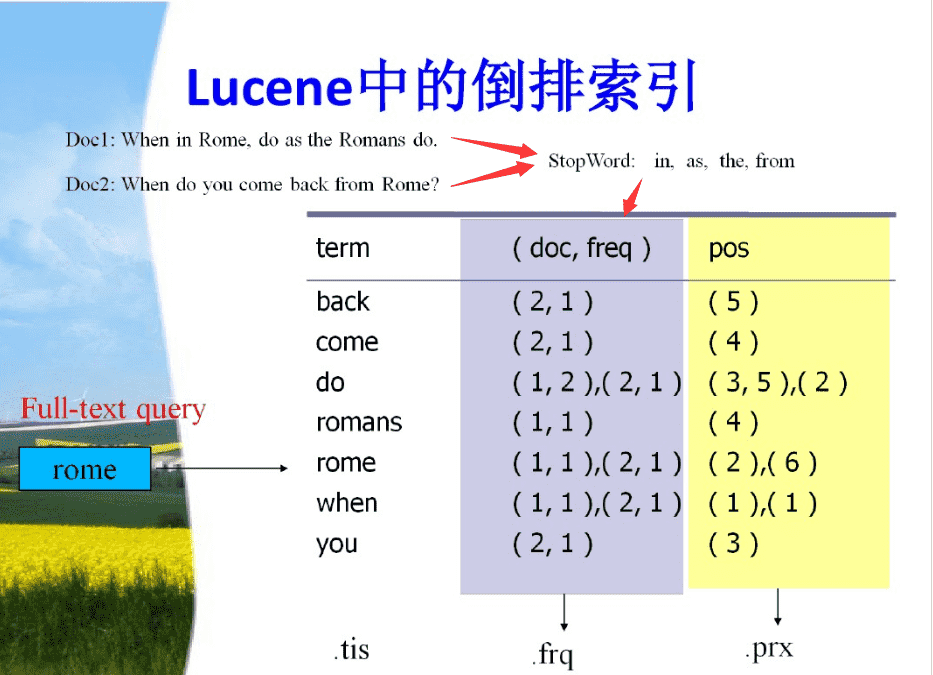
2. 停用词:在一段句子中,去掉之后对句子的表达意向没有印象的词语,如“非常”、“如果”,中文中主要包括冠词,副词等。
3. 排序:搜索引擎在对一个关键词进行搜索时,可能会命中许多文档,这个时候,搜索引擎就需要快速的查找的用户所需要的文档,因此,相关度大的结果需要进行排序,这个设计到搜索引擎的相关度算法。
### Lucene中的几个概念
1. 文档(Document):文档是一系列域的组合,文档的域则代表一系列域文档相关的内容。
2. 域(Field):每个文档可以包含一个或者多个不同名称的域。
3. 词(Term):Term是搜索的基本单元,与Field相对应,包含了搜索的域的名称和关键词。
4. 查询(Query):一系列Term的条件组合,成为TermQuery,但也有可能是短语查询等。
5. 分词器(Analyzer):主要是用来做分词以及去除停用词的处理。
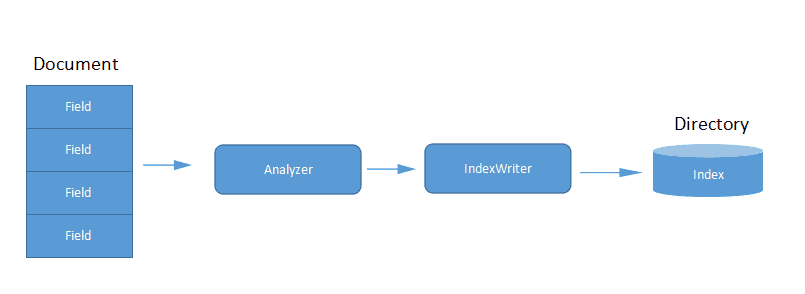
索引的建立
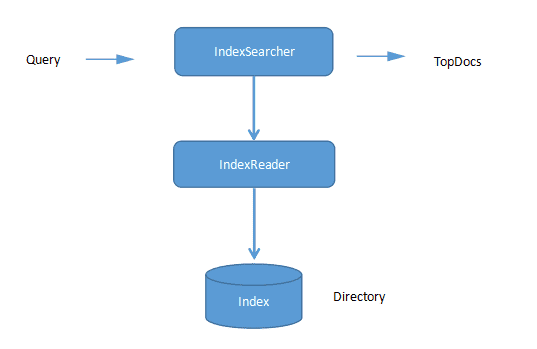
索引的搜索
### lucene在本网站的使用:
1. 搜索 2. 自动分词
## 一、搜索
注意:本文使用最新的lucene,版本6.6.0。lucene的版本更新很快,每跨越一次大版本,使用方式就不一样。首先需要导入lucene所使用的包。使用maven:
```java
org.apache.lucene
lucene-core
${lucene.version}
org.apache.lucene
lucene-analyzers-common
${lucene.version}
org.apache.lucene
lucene-analyzers-smartcn
${lucene.version}
org.apache.lucene
lucene-queryparser
${lucene.version}
org.apache.lucene
lucene-highlighter
${lucene.version}
```
1. 构建索引
```java
Directory dir = FSDirectory.open(Paths.get("blog_index"));//索引存储的位置
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();//简单的分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(dir, config);
Document doc = new Document();
doc.add(new TextField("title", blog.getTitle(), Field.Store.YES)); //对标题做索引
doc.add(new TextField("content", Jsoup.parse(blog.getContent()).text(), Field.Store.YES));//对文章内容做索引
writer.addDocument(doc);
writer.close();
```
2. 更新与删除
```java
IndexWriter writer = getWriter();
Document doc = new Document();
doc.add(new TextField("title", blog.getTitle(), Field.Store.YES));
doc.add(new TextField("content", Jsoup.parse(blog.getContent()).text(), Field.Store.YES));
writer.updateDocument(new Term("blogid", String.valueOf(blog.getBlogid())), doc); //更新索引
writer.close();
```
3. 查询
```java
private static void search_index(String keyword) {
try {
Directory dir = FSDirectory.open(Paths.get("blog_index")); //获取要查询的路径,也就是索引所在的位置
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
QueryParser parser = new QueryParser("content", analyzer); //查询解析器
Query query = parser.parse(keyword); //通过解析要查询的String,获取查询对象
TopDocs docs = searcher.search(query, 10);//开始查询,查询前10条数据,将记录保存在docs中,
for (ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("title")); //fullPath是刚刚建立索引的时候我们定义的一个字段
}
reader.close();
} catch (IOException | ParseException e) {
logger.error(e.toString());
}
}
```
4. 高亮
```java
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, scorer);
highlighter.setTextFragmenter(fragmenter);
for (ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
String title = doc.get("title");
TokenStream tokenStream = analyzer.tokenStream("title", new StringReader(title));
String hTitle = highlighter.getBestFragment(tokenStream, title);
System.out.println(hTitle);
}
```
结果
```html
Java堆.栈和常量池 笔记
```
5. 分页 目前lucene分页的方式主要有两种: (1). 每次都全部查询,然后通过截取获得所需要的记录。由于采用了分词与倒排索引,所有速度是足够快的,但是在数据量过大的时候,占用内存过大,容易造成内存溢出 (2). 使用searchAfter把数据保存在缓存里面,然后再去取。这种方式对大量的数据友好,但是当数据量比较小的时候,速度会相对慢。 lucene中使用searchafter来筛选顺序
```java
ScoreDoc lastBottom = null;//相当于pageSize
BooleanQuery.Builder booleanQuery = new BooleanQuery.Builder();
QueryParser parser1 = new QueryParser("title", analyzer);//对文章标题进行搜索
Query query1 = parser1.parse(q);
booleanQuery.add(query1, BooleanClause.Occur.SHOULD);
TopDocs hits = search.searchAfter(lastBottom, booleanQuery.build(), pagehits); //lastBottom(pageSize),pagehits(pagenum)
```
6. 使用效果 全部代码放在[这里](https://github.com/Zephery/newblog/blob/master/src/main/java/com/myblog/lucene/BlogIndex.java),代码写的不太好,光从代码规范上就不咋地。在网页上的使用效果如下:
## 二、lucene自动补全
百度、谷歌等在输入文字的时候会弹出补全框,如下图:

在搭建lucene自动补全的时候,也有考虑过使用SQL语句中使用like来进行,主要还是like对数据库压力会大,而且相关度没有lucene的高。主要使用了官方suggest库以及[autocompelte.js](https://github.com/xdan/autocomplete/)这个插件。 suggest的原理[看这](http://iamyida.iteye.com/blog/2205114),以及索引结构[看这](http://blog.csdn.net/u011389474/article/details/69458445)。
#### 使用:
1. 导入maven包
```xml
org.apache.lucene
lucene-suggest
6.6.0
```
2. 如果想将结果反序列化,声明实体类的时候要加上:
```java
public class Blog implements Serializable {
```
3. 实现InputIterator接口
```
InputIterator的几个方法:
long weight():返回的权重值,大小会影响排序,默认是1L
BytesRef payload():对某个对象进行序列化
boolean hasPayloads():是否有设置payload信息
Set contexts():存入context,context里可以是任意的自定义数据,一般用于数据过滤
boolean hasContexts():判断是否有下一个,默认为false
```
```java
public class BlogIterator implements InputIterator {
/**
* logger
*/
private static final Logger logger = LoggerFactory.getLogger(BlogIterator.class);
private Iterator blogIterator;
private Blog currentBlog;
public BlogIterator(Iterator blogIterator) {
this.blogIterator = blogIterator;
}
@Override
public boolean hasContexts() {
return true;
}
@Override
public boolean hasPayloads() {
return true;
}
public Comparator getComparator() {
return null;
}
@Override
public BytesRef next() {
if (blogIterator.hasNext()) {
currentBlog = blogIterator.next();
try {
//返回当前Project的name值,把blog类的name属性值作为key
return new BytesRef(Jsoup.parse(currentBlog.getTitle()).text().getBytes("utf8"));
} catch (Exception e) {
e.printStackTrace();
return null;
}
} else {
return null;
}
}
/**
* 将Blog对象序列化存入payload
* 可以只将所需要的字段存入payload,这里对整个实体类进行序列化,方便以后需求,不建议采用这种方法
*/
@Override
public BytesRef payload() {
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bos);
out.writeObject(currentBlog);
out.close();
BytesRef bytesRef = new BytesRef(bos.toByteArray());
return bytesRef;
} catch (IOException e) {
logger.error("", e);
return null;
}
}
/**
* 文章标题
*/
@Override
public Set contexts() {
try {
Set regions = new HashSet();
regions.add(new BytesRef(currentBlog.getTitle().getBytes("UTF8")));
return regions;
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Couldn't convert to UTF-8");
}
}
/**
* 返回权重值,这个值会影响排序
* 这里以产品的销售量作为权重值,weight值即最终返回的热词列表里每个热词的权重值
*/
@Override
public long weight() {
return currentBlog.getHits(); //change to hits
}
}
```
4. ajax 建立索引
```java
/**
* ajax建立索引
*/
@Override
public void ajaxbuild() {
try {
Directory dir = FSDirectory.open(Paths.get("autocomplete"));
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester(dir, analyzer);
//创建Blog测试数据
List blogs = blogMapper.getAllBlog();
suggester.build(new BlogIterator(blogs.iterator()));
} catch (IOException e) {
System.err.println("Error!");
}
}
```
5. 查找\
因为有些文章的标题是一样的,先对list排序,将标题短的放前面,长的放后面,然后使用LinkHashSet来存储。
```java
@Override
public Set ajaxsearch(String keyword) {
try {
Directory dir = FSDirectory.open(Paths.get("autocomplete"));
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester(dir, analyzer);
List list = lookup(suggester, keyword);
list.sort(new Comparator() {
@Override
public int compare(String o1, String o2) {
if (o1.length() > o2.length()) {
return 1;
} else {
return -1;
}
}
});
Set set = new LinkedHashSet<>();
for (String string : list) {
set.add(string);
}
ssubSet(set, 7);
return set;
} catch (IOException e) {
System.err.println("Error!");
return null;
}
}
```
6. controller层
```java
@RequestMapping("ajaxsearch")
public void ajaxsearch(HttpServletRequest request, HttpServletResponse response) throws IOException {
String keyword = request.getParameter("keyword");
if (StringUtils.isEmpty(keyword)) {
return;
}
Set set = blogService.ajaxsearch(keyword);
Gson gson = new Gson();
response.getWriter().write(gson.toJson(set));//返回的数据使用json
}
```
7. ajax来提交请求 autocomplete.js源代码与介绍:
```js
```
8. 效果:\

#### 欢迎访问我的[个人网站](http://www.wenzhihuai.com/)
参考:\